來源:華爾街見聞
4月8日華為發布了盤古大模型,引發業內高度關注。盤古NLP大模型在三方面實現了突破性進展。
第一、具備先進的語言理解和模型生成能力,盤古NLP大模型在權威的中文語言理解評測基準CLUE總排行榜及分類、閱讀理解單項均排名第一,刷新三項榜單世界歷史記錄;
第二、在預訓練階段沉澱了大量的通用知識,僅能做到理解又能做到生成,除了像GPT-3等基於端到端的生產方式之外,還能夠通過少量樣本學習對意圖進行識別,轉化為知識庫和數據庫查詢。
第三、采用大模型小樣本的調優路線,實現小樣本學習任務上超越GPT系列。
華爾街見聞·見智研究認為:人工智能的發展就是從小模型到大模型,未來幾年大模型的研發浪潮將會加速推動AI行業的快速發展,並且將滲透到眾多行業中。
專用模型下,數據安全被重視
在細分領域下,行業數據會直接影響到技術迭代速度、商業競爭等,被看作是大模型訓練的“黃金鑰匙”,這也是為什麽現在各個國家將數據安全提高至最高等級。
此前,三星半導體部門就曾發生數據安全泄露的重大事故。
根據韓國媒體 Economist 的報道,出於擔心可能發生的內部機密信息泄露,三星一直阻止其員工在工作場所使用 ChatGPT。不過從 3 月 11 日起,三星向其半導體部門的員工授予了 ChatGPT 的使用權限(其他部門仍被禁止)。在三星員工使用 ChatGPT 來幫助他們完成工作時,三星的機密數據也不知不覺就泄露了。
所以,行業數據安全在大模型中需要有很高的安全性保證。基於這點來看,也催生出各個領域的巨頭對大模型研發的渴求,畢竟關鍵的數據將直接影響公司商業價值的時間長度。
接下來,多家巨頭都將會宣布陸續發布自家的大模型。
(預計)4月10日$商湯-W(00020.HK)$發布大模型
(預計)4月11日$阿里巴巴-SW(09988.HK)$發布大模型
(預計)4月14日同花順發布AI產品
(預計)5月6日科大訊飛發布大模型
(預計)5月$騰訊控股(00700.HK)$發布混元大模型
而對於沒有很強資金實力的公司來說,盤古大模型就可以提供很好的數據訓練。
從盤古大模型來看為例,劃分為L0-L1-L2三個層級:
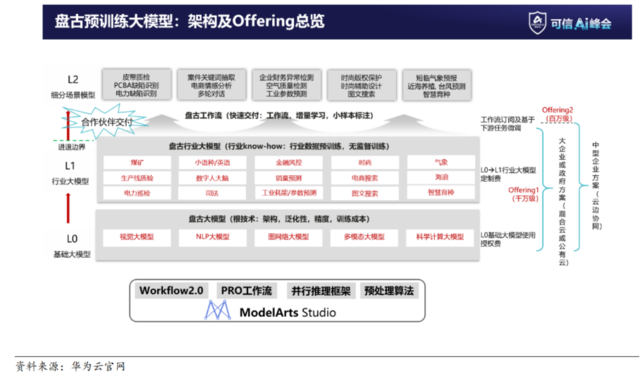
L0層級:包含視覺大模型:部分應用場景成績位居世界第一,包括礦山場景、鐵路作業故障檢測等等;NLP大模型也就是上文提到的自然語言大模型;圖網絡大模型、多模態大模型以及科學計算大模型。
L1層級:是基礎模型與行業數據結合後的混合大模型,需要有很高的know-how經驗,這也就決定了行業大模型的垂直性,並且還要重點關注模型內的訓練參數質量和安全性。
L2層級:是把L1層級下有業務場景進行部署後生成的細分場景模型,更具有專用性。
見智研究認為:特別是在L1和L2層級下,盤古大模型能夠極大程度的幫助各行各業進行定製化訓練,並且減少基礎大模型的高昂研發費用,同時還能保證數據安全。
小結:人工智能的時速競賽才剛剛啟程,接下來會是大模型的商業廝殺,誰越早發布、質量越高、數據安全性越高,就能搶先獲得客戶青睞,可謂是分秒必爭的時刻。
編輯/new