來源:智東西
智東西4月6日消息,根據Meta官方博客,Meta在本周三推出了一個AI模型Segment Anything Model(SAM,分割一切模型),能夠根據文本指令等方式實現圖像分割,而且萬物皆可識別和一鍵摳圖。
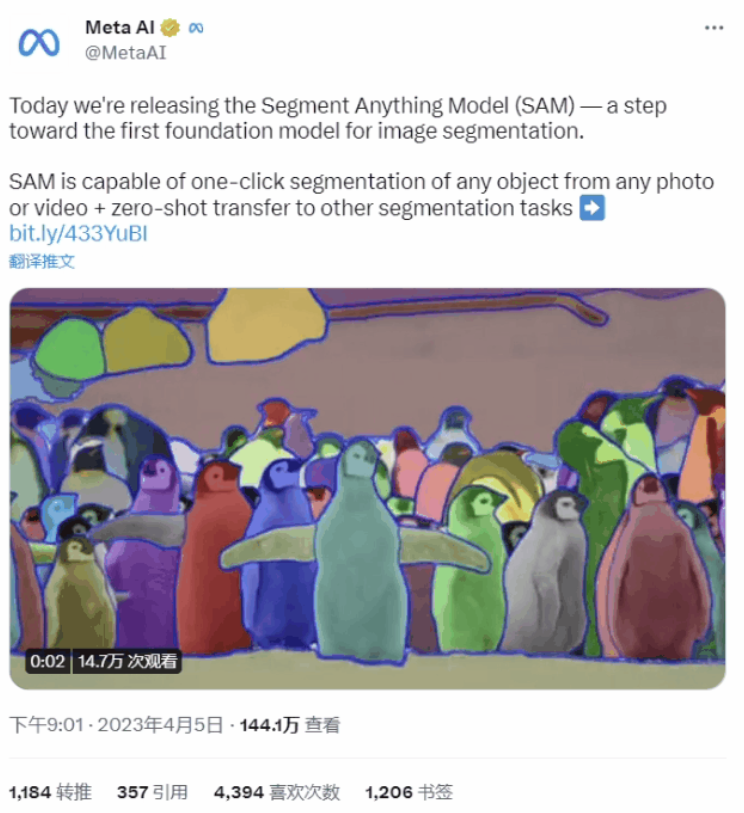
Meta在博客中稱,SAM的靈活性在圖像分割領域內屬首創,SAM以交互式方式標注一個掩碼(mask)僅需約14秒。英偉達AI研究科學家Jim Fan稱,該模型的發布是計算機視覺領域的“GPT-3時刻”,因為該模型能對從未訓練過的圖片進行精準分割。在推出SAM的同時,Meta還發布了一個圖像注釋數據集Segment Anything 1-Billion mask(SA-1B),該數據集包含超11億個掩碼,據稱是同類數據集中最大的。
目前,Meta內部已經在使用SAM技術來進行標記照片、審核內容以及向Facebook和Instagram用戶推薦內容等,同時更多在VR/AR、智慧農業等領域的顛覆性應用暢想也在官網展示了出來。
Meta研發團隊在官網上發布了關於Segment Anything的論文細節。
論文鏈接:https://ai.facebook.com/research/publications/segment-anything/
一、鼠標停留、手動框選、自動分割,三種方式實現圖像切割
SAM可以識別圖像和視頻中的任何物體,即使是在此前的訓練過程中從未遇到過的。Meta官網中提供了SAM的免費演示,並為用戶提供了三種分割圖像部分的方法:
一是“懸停和點擊(Hover&Click)”,當用戶把鼠標放在想要分割出的部分上並點擊時,SAM會自動提取出該部分。

二是“方框(Boxing)”,用戶將自己想要的部分框定出來,SAM會識別其中的物體並將其與背景進行分割。

三是“全選(Everything)”,在這種模式下SAM會自動識別圖像內的所有物體。

雖然還沒有發布產品,但Meta已展示了SAM的部分功能,目前官網介紹的功能包括:用交互點式和手動框定來選擇物體;

SAM自動分割圖像中的所有內容;

自動給不明確的提示生成多個valid mask(有效掩碼),讓用戶能精準選中圖像;

此外,SAM還可與其它系統靈活集成,從其它系統中獲取輸入提示,比如,從AR/VR頭顯中獲取用戶的視線範圍來選擇對象,甚至還能將看到的物體轉換成為3D對象。

SAM還能啟用文本框輸入來檢測界定對象,當用戶在文本框中輸入“cat(貓)”這個單詞時,SAM會框定住圖像中所有的貓,並在框中精確選取貓的整個圖像輪廓。

SAM的有效輸出掩碼(valid mask)還可以用作其他AI系統的輸入,如當用戶選中一張椅子的圖片後,SAM可以精確選中,並在視頻中跟蹤物體遮罩,自動啟用圖像編輯應用程序,把靜態物體轉化為3D或是碎片拼貼等狀態。

二、領域內首創:由1000萬張圖片訓練,可提取11億+掩碼
在自然語言處理和計算機視覺領域,基礎模型是其發展的重要基礎,基礎模型可以使用“prompting(促進)”技術對新數據集和任務執行零樣本和少樣本學習。Meta從中汲取了靈感,並對SAM模型進行訓練。
在Meta發布一篇論文中,研發團隊人員詳細介紹了SAM的相關細節。

常見的圖像分割方式包括兩種,一是交互式分割,二是自動分割。前者需要工程師通過迭代完善一個遮罩來指導模型,後者是模型在經過數百或數千個注釋對象的訓練後自行完成,但同樣需要訓練者手動標注分割對象。
這兩種方法都無法實現全自動的圖像分割,而SAM將二者的功能進行融合。在模型的提示界面上,用戶只需要為模型提供正確的提示,比如點擊、框選或是文本指令,模型就可以完成全自動的圖像分割任務。這就意味著,用戶不再需要收集自己的細分數據來微調模型。


在引擎蓋下,輕量級編碼器將任何提示實時轉換為嵌入向量(embedding vector),然後將信息源組合在一個預測分割掩碼的輕量級解碼器中。在計算圖像嵌入後,SAM 50毫秒內就能根據網絡瀏覽器中的任何提示生成一個切割好的圖像。
論文中稱,SAM能根據輸入提示為圖像中所有對象生成高質量的對象掩碼(mask),用於訓練SAM的SA-1B圖像數據集目前包含超過11億個掩碼,這些掩碼是從1100萬張已經獲得許可、並且保護隱私的高分辨率圖像中收集的,這些圖像的分辨率達到了1500×2250 pixels,平均每張圖像約有100個掩碼。

Meta在論文中指出,有了SAM模型,收集新分割掩碼的速度遠超以往,交互式標注一個掩碼現在只需要約14秒。其數據集數量也是現在任何一個數據集的400倍。這種高自動化、高靈活性的圖像分割技術為領域內首創。

三、CV領域的“GPT-3時刻”,或變革VR/AR
Meta官方稱,通過在業內共享這項研究和數據集,公司希望進一步加速對分割圖像視頻的研究。這款可提示分割模型可以作為更大系統中的組件來執行分割任務。Meta預計,SAM或將成為AR/VR、內容創作等領域的強大組件之一,有望創造出更為通用的AI系統。
英偉達AI研究科學家Jim Fan稱“今天是計算機視覺領域的‘GPT-3 時刻’之一”,SAM已經了解了“對象”的概念,甚至對於不熟悉乃至未知的場景和那些模棱兩可的情況,它都能進行切割。Jim稱難以想象它的模型和數據居然都是開源的。
他指出了SAM的秘訣:
1、一個非常簡單但可擴展的架構,采用文本、關鍵點、邊框等多種提示模式;
2、與模型設計密切相關的人工操作渠道;
3、一個數據飛輪,允許模型自主學習那些未標記的圖像。

紮克伯格稱,將這種生成式AI作為“創意輔助工具”納入到Meta的應用程序中是今年工作目標的重中之重。
目前,SAM模型和數據集僅在非商用許可下提供下載,用戶在將自己的圖片上傳到原型上時,必須承諾不將其用作研究。
未來,SAM可用於通過AR眼鏡識別日常物品,向用戶發出提醒和指示。

SAM也將對其他領域產生影響,比如指導農民進行糧食生產或協助生物學家進行研究等。

結語:圖像分割再進化,Meta掀起CV革命?
圖像分割技術並非是新鮮事,但SAM能識別出訓練數據集中不存在的物體,或許將會引發新一輪AI視覺應用潮。未來,Meta通過分享他們的研究和數據集,將會使這類組合系統設計在多個領域得到廣泛應用。SAM將會是內容創作、圖像生成等更為普遍的AI領域的一個強大組件,讓圖像識別和視覺內容的語義理解之間更好耦合,釋放出更強大的AI潛力。
來源:Meta官方、路透社
編輯/hoten